Tout dépend de votre organisation, de vos clients, et surtout de votre tolérance au risque. Mais avec le temps, j’ai fini par utiliser un cadre d’analyse simple qui permet de rendre cette décision beaucoup plus concrète.
Tout se résume à deux variables :
- le rayon d’impact (blast radius)
- la réversibilité
1. Le rayon d’impact : jusqu’où les dégâts peuvent aller
Le rayon d’impact représente le niveau de dommage potentiel si l’agent se trompe.
Un agent qui rédige des comptes-rendus de réunions internes a un faible rayon d’impact.
S’il commet une erreur, quelqu’un la corrige rapidement.
En revanche, un agent qui envoie des livrables directement aux clients possède un rayon d’impact plus élevé.
Une mauvaise information peut provoquer une incompréhension, une perte de confiance… voire obliger votre équipe Customer Success à gérer une situation délicate au téléphone.
Et un agent chargé de recommander des traitements médicaux à des milliers de patients ?
Là, on parle d’un rayon d’impact énorme : des vies humaines peuvent être concernées.
2. La réversibilité : peut-on corriger facilement l’erreur ?
La deuxième variable est la réversibilité.
Autrement dit : une fois l’action effectuée, est-il simple de revenir en arrière ?
Un agent qui génère un brouillon qu’un humain valide avant envoi est hautement réversible.
On peut modifier, corriger ou annuler.
À l’inverse, un agent qui pousse directement des changements dans une application, ou diffuse des informations vers l’extérieur, l’est beaucoup moins.
Prenez l’exemple des fuites de données liées à l’IA : une fois l’information exposée publiquement, il est pratiquement impossible de la récupérer.
On ne “rappelle” pas des données comme on annule un email.
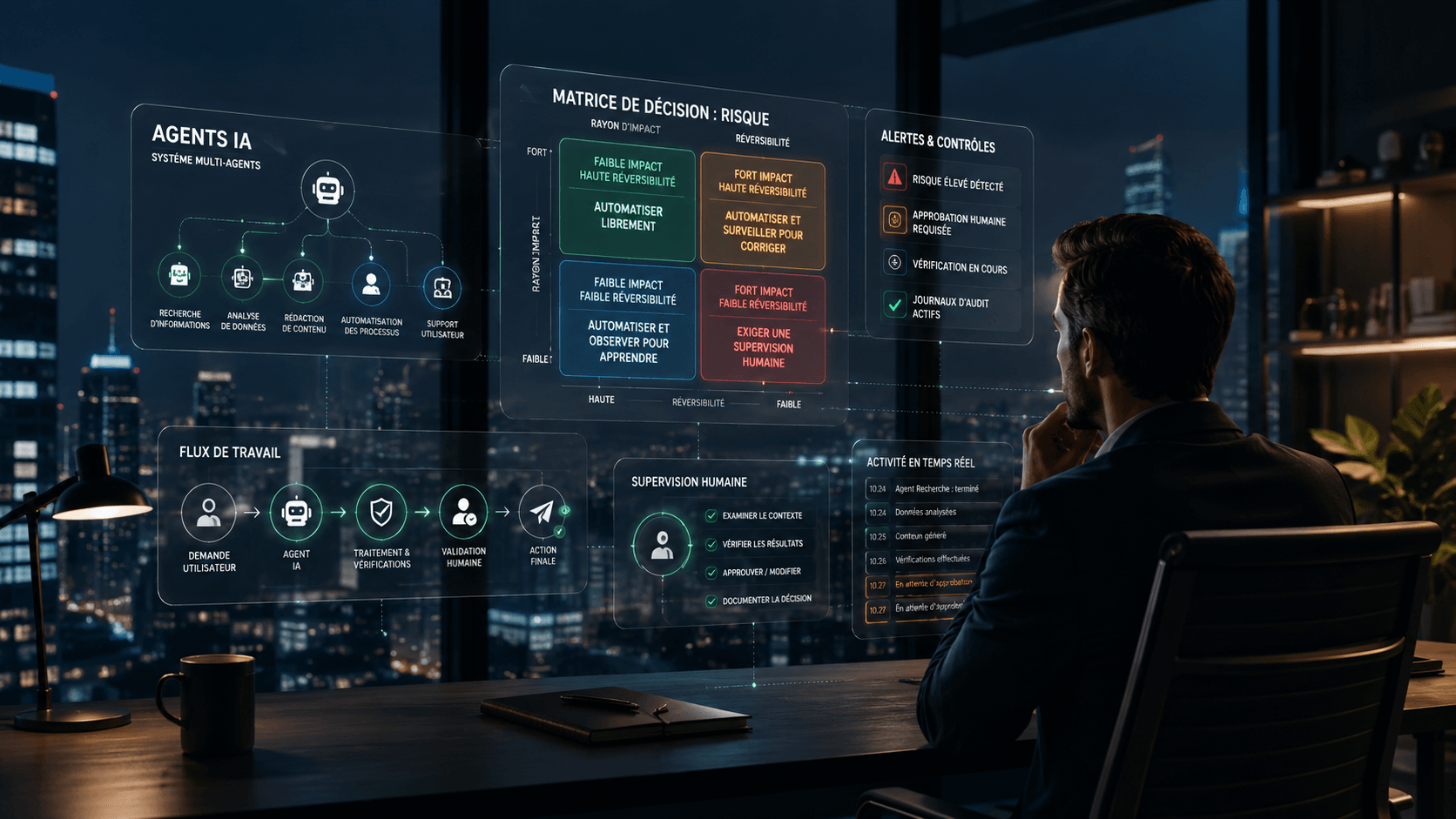
Une matrice simple pour prioriser vos usages IA
Ces deux dimensions permettent de construire une grille de décision extrêmement utile.
Faible impact + forte réversibilité
→ Automatisez sans hésiter
C’est le meilleur point de départ.
On parle ici :
- d’outils internes,
- d’assistants de productivité,
- de tâches où le pire scénario représente quelques minutes de correction.
Le risque est faible, et c’est précisément dans ces usages que les équipes apprennent comment les agents IA se comportent réellement.
Faible impact + faible réversibilité
→ Automatisez, mais observez attentivement
Les conséquences restent limitées, mais l’erreur laisse une trace durable.
Exemples :
- un agent qui publie automatiquement dans un canal interne,
- un système qui écrit dans une base de données permanente.
Les enjeux ne sont pas critiques, mais il faut surveiller les comportements de l’agent pour comprendre :
- ce qu’il fait correctement,
- où il échoue,
- comment améliorer son fonctionnement avant de lui confier des missions plus sensibles.
Fort impact + forte réversibilité
→ Automatisez avec validation humaine
Ici, le risque devient sérieux, mais les erreurs peuvent encore être interceptées avant de produire des conséquences importantes.
Exemple typique :
- un brouillon d’email destiné à un client,
- relu rapidement par un humain avant l’envoi.
Vous bénéficiez alors :
- de la rapidité de l’automatisation,
- sans abandonner le contrôle final.
C’est souvent le meilleur compromis entre efficacité et sécurité.
Fort impact + faible réversibilité
→ Supervision humaine obligatoire
C’est la zone où il ne faut pas jouer aux apprentis sorciers.
On parle notamment :
- de communications stratégiques envoyées à des clients,
- de modifications directes dans votre infrastructure applicative,
- ou de toute action impossible à annuler une fois exécutée.
Chez Section, par exemple, nous envoyons un brief client après chaque premier rendez-vous afin de résumer les échanges et proposer des recommandations initiales.
L’IA participe à la rédaction de ces documents.
Mais comme ils sont destinés à des dirigeants, ils font systématiquement l’objet d’une relecture humaine approfondie — et sont souvent fortement modifiés avant envoi.
Le vrai objectif : apprendre avec des erreurs peu coûteuses
L’idée n’est pas d’éviter toute erreur.
C’est impossible.
Le véritable objectif est de commencer par des cas :
- à faible impact,
- facilement réversibles,
afin d’apprendre comment les agents se comportent avant de les déployer dans des environnements critiques.
Autrement dit :
Faites vos premières erreurs là où elles coûtent peu.
Ce que les entreprises doivent comprendre maintenant
Si vous débutez avec les agents IA, commencez simple.
Construisez des automatisations internes, peu risquées, faciles à contrôler.
Mais attention : ne restez pas bloqué éternellement sur ces usages “safe”.
Les gains de valeur les plus importants apparaîtront justement dans les workflows complexes et à forts enjeux.
Les premiers déploiements servent avant tout à développer :
- les bons réflexes,
- les garde-fous,
- et le jugement organisationnel nécessaire pour gérer la suite.
Parce qu’au final, le défi n’est pas simplement de déployer des agents IA.
Le vrai défi, c’est de savoir jusqu’où vous pouvez leur faire confiance.